

Multicloud Object Gateway for Single-Node OpenShift (SNO)
Author: Brandon B. Jozsa
"Remember, there's no such thing as a small act of kindness. Every act creates a ripple with no logical end."
- Scott Adams
- Part I: Introduction
- Part II: Multicloud Object Storage
- Part III: Installation of MCG
- Part IV: Enabling the UI Plugins for MCG
- Part V: Creating S3 Bucket Claims
- Part VI: Using S3 Object Buckets
- Final Thoughts
Part I: Introduction
So you've deployed a fresh, new Single-Node OpenShift environment. Now what do you do? Well, you can only get so far without storage for your workloads. In the past, Red Hat has suggested using the Local Storage Operator (LSO) or Hostpath Provisioner (HPP), but there's one glaring storage option missing, and this is especially true in the age of AI: object storage.
The most common protocol for object storage is of course Amazon's implementation of S3, and what most people may not realize is that you can implement this object storage option within your own SNO-based clusters, as well as multi-node environments (compact or full deployments). This leads us to the OpenShift Multicloud Object Storage (MCG) operator, provided by Red Hat (via the NooBaa project). Let's get started, because this is going to be a fun one today!
Part II: Multicloud Object Storage
There are quite a few benefits to leveraging the MCG solution for a SNO environment. For one, MCG is very light-weight. This is especially true when comparing against other solutions, such as Ceph's own S3 offering. Similar to Ceph's Object Gateway, the MCG can be leveraged by applications that are currently using Amazon's AWS S3 SDK. In order to use the MCG on premise for example, you simply need to target the MCG endpoint and provide the appropriate access and secret access keys (more on this below). Even better is the fact that MCG democratizes your S3 endpoints across cloud providers to avoid cloud lock-in.
But this also means that you can leverage the power of AI within your SNO clusters for tasks such as training AI models, without having to deploy heavier alternatives such as Ceph or other community-based options like MinIO. You can use Red Hat's very own OpenShift Data Foundation - but in this case, you're just using a very small subset of the operator deployment.
Part III: Installation of MCG
A prerequisite of running the MCG operator is that you still need storage of some sort installed. What we will be using in this guide will be provided via the LVM Operator by the Red Hat OpenShift team.
STOP: Be sure to review my other blog post for details about installing the LVM Operator on OpenShift.
-
With the LVM Operator installed, I am going to assume that you have a
StorageClassnamedlvms-vg1-immediateready to be used by the MCG.
STOP AND REVIEW the following manifest. OpenShift Data Foundation uses release versions as part of theirsub.spec.channel, so be absolutely sure that you're either running OpenShift 4.16 or change the channel to match your version of OpenShift (i.e.channel: "stable-4.16").cat <<EOF | oc apply -f - --- apiVersion: v1 kind: Namespace metadata: labels: openshift.io/cluster-monitoring: "true" name: openshift-storage --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: openshift-storage-operatorgroup namespace: openshift-storage spec: targetNamespaces: - openshift-storage --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: odf-operator namespace: openshift-storage spec: name: odf-operator source: redhat-operators sourceNamespace: openshift-marketplace channel: "stable-4.16" installPlanApproval: Automatic EOF -
Once the ODF operator has been installed, you can review the status of the operator with the following command.
while true; do oc get csv -n openshift-storage | awk 'NR==1 || /odf/' sleep 2 clear doneThis will result in the following output:
NAME DISPLAY VERSION REPLACES PHASE mcg-operator.v4.16.3-rhodf NooBaa Operator 4.16.3-rhodf mcg-operator.v4.16.2-rhodf Succeeded ocs-client-operator.v4.16.3-rhodf OpenShift Data Foundation Client 4.16.3-rhodf ocs-client-operator.v4.16.2-rhodf Succeeded ocs-operator.v4.16.3-rhodf OpenShift Container Storage 4.16.3-rhodf ocs-operator.v4.16.2-rhodf Succeeded odf-csi-addons-operator.v4.16.3-rhodf CSI Addons 4.16.3-rhodf odf-csi-addons-operator.v4.16.2-rhodf Succeeded odf-operator.v4.16.3-rhodf OpenShift Data Foundation 4.16.3-rhodf odf-operator.v4.16.2-rhodf Succeeded odf-prometheus-operator.v4.16.3-rhodf Prometheus Operator 4.16.3-rhodf odf-prometheus-operator.v4.16.2-rhodf Succeeded recipe.v4.16.3-rhodf Recipe 4.16.3-rhodf recipe.v4.16.2-rhodf Succeeded rook-ceph-operator.v4.16.3-rhodf Rook-Ceph 4.16.3-rhodf rook-ceph-operator.v4.16.2-rhodf Succeeded -
Once the ODF operator has reached a
PHASEofSucceeded, use the following manifest to install the MCG object storage solution to your SNO deployment. This will not install any other ODF components to your environment. It will only install the NooBaa MCG.cat <<EOF | oc apply -f - apiVersion: ocs.openshift.io/v1 kind: StorageCluster metadata: annotations: uninstall.ocs.openshift.io/cleanup-policy: delete uninstall.ocs.openshift.io/mode: graceful name: ocs-storagecluster namespace: openshift-storage spec: arbiter: {} encryption: kms: {} externalStorage: {} resourceProfile: "lean" enableCephTools: false allowRemoteStorageConsumers: false managedResources: cephObjectStoreUsers: {} cephCluster: {} cephBlockPools: {} cephNonResilientPools: {} cephObjectStores: {} cephFilesystems: {} cephRBDMirror: {} cephToolbox: {} cephDashboard: {} cephConfig: {} mirroring: {} multiCloudGateway: dbStorageClassName: lvms-vg1-immediate reconcileStrategy: standalone disableLoadBalancerService: true EOF -
Once again, review the
csvinstallation phase and wait until everything is in aSucceededphase.while true; do oc get csv -n openshift-storage | awk 'NR==1 || /odf/' sleep 2 clear done -
Now you must label the node (which is a requirement for NooBaa to be installed correctly).
NODE_NAME=$(oc get no -o name) oc label $NODE_NAME cluster.ocs.openshift.io/openshift-storage='' -
Now you can debug the installation with the following command. Be sure to use these instructions to install the
noobaacommand first.noobaa status -n openshift-storageThis will provide similar output to what is shown below (which is just a snippet of the most important logs)
INFO[0000] System Wait Ready: INFO[0000] ⏳ System Phase is "Connecting". Pod "noobaa-core-0" is not yet ready: Phase="Pending". (). ContainersNotReady (containers with unready status: [core noobaa-log-processor]). ContainersNotReady (containers with unready status: [core noobaa-log-processor]). INFO[0022] ⏳ System Phase is "Connecting". Waiting for phase ready ... INFO[0025] ⏳ System Phase is "Connecting". Waiting for phase ready ... INFO[0058] ⏳ System Phase is "Configuring". Waiting for phase ready ... INFO[0061] ⏳ System Phase is "Configuring". Waiting for phase ready ... INFO[0064] ✅ System Phase is "Ready". INFO[0064] System Status: INFO[0064] ✅ Exists: NooBaa "noobaa" INFO[0064] ✅ KMS status: "Sync" INFO[0064] ✅ Exists: StatefulSet "noobaa-core" INFO[0064] ✅ Exists: ConfigMap "noobaa-config" INFO[0064] ✅ Exists: Service "noobaa-mgmt" INFO[0064] ✅ Exists: Service "s3" INFO[0064] ✅ Exists: Service "sts" INFO[0064] ✅ Exists: Secret "noobaa-db" INFO[0064] ✅ Exists: ConfigMap "noobaa-postgres-config" INFO[0064] ❌ Not Found: ConfigMap "noobaa-postgres-initdb-sh" INFO[0064] ✅ Exists: StatefulSet "noobaa-db-pg" INFO[0064] ✅ Exists: Service "noobaa-db-pg" INFO[0064] ✅ Exists: Secret "noobaa-server" INFO[0064] ✅ Exists: Secret "noobaa-operator" INFO[0064] ✅ Exists: Secret "noobaa-endpoints" INFO[0064] ✅ Exists: Secret "noobaa-admin" INFO[0064] ✅ Exists: StorageClass "openshift-storage.noobaa.io" INFO[0064] ✅ Exists: BucketClass "noobaa-default-bucket-class" INFO[0064] ✅ Exists: Deployment "noobaa-endpoint" INFO[0064] ✅ (Optional) Exists: BackingStore "noobaa-default-backing-store" INFO[0064] ⬛ (Optional) Not Found: CredentialsRequest "noobaa-aws-cloud-creds" INFO[0064] ⬛ (Optional) Not Found: CredentialsRequest "noobaa-azure-cloud-creds" INFO[0064] ⬛ (Optional) Not Found: Secret "noobaa-azure-container-creds" INFO[0064] ⬛ (Optional) Not Found: Secret "noobaa-gcp-bucket-creds" INFO[0064] ⬛ (Optional) Not Found: CredentialsRequest "noobaa-gcp-cloud-creds" INFO[0064] ✅ (Optional) Exists: PrometheusRule "noobaa-prometheus-rules" INFO[0064] ✅ (Optional) Exists: ServiceMonitor "noobaa-mgmt-service-monitor" INFO[0064] ✅ (Optional) Exists: ServiceMonitor "s3-service-monitor" INFO[0064] ✅ (Optional) Exists: Route "noobaa-mgmt" INFO[0064] ✅ (Optional) Exists: Route "s3" INFO[0064] ✅ (Optional) Exists: Route "sts" INFO[0064] ✅ Exists: PersistentVolumeClaim "db-noobaa-db-pg-0" INFO[0064] ✅ System Phase is "Ready" INFO[0064] ✅ Exists: "noobaa-admin"This will be followed by all of your endpoint, user, and password information for your new NooBaa environment. You're all ready to go and you can start using NooBaa within your cluster!
Part IV: Enabling the UI Plugins for MCG
To make your experience a little nicer, you can enable the UI plugins for MCG by running through the following simple steps.
OpenShift Data Foundation Plugin
-
Within the OpenShift console, navigate to Operators > Installed Operators > OpenShift Data Foundation.
-
In this view, on the far right-hand side, you will see a comment entitled Console plugin, and under that a hyperlink that says Disabled. Click on this hyperlink.
-
Click on the Enable radio button, and then click the blue Save button.
OpenShift Data Foundation Client Plugin
-
Next, within the OpenShift console, navigate to Operators > Installed Operators > OpenShift Data Foundation Client.
-
In this view, on the far right-hand side, you will see a comment entitled Console plugin, and under that a hyperlink that says Disabled. Click on this hyperlink.
-
Click on the Enable radio button, and then click the blue Save button.
Part V: Creating S3 Bucket Claims
Now we come to the really fun part: how to use MCG to create object storage buckets for workloads!
-
Let's create a project first, and then create a custom
ObjectBucketClaim. We'll try to use thisobcfurther in our tutorial.❯ oc create ns ai-testing namespace/ai-testing created -
Next, let's create the
ObjectBucketClaimfor that project.cat <<EOF | oc apply -f - --- apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: test01-obc namespace: ai-testing spec: bucketName: test01-obc storageClassName: openshift-storage.noobaa.io EOF -
Now you want to get some information, as well as the credentials for the
obcthat you just created. Use the following commands to do this. Please note the variables used for the command, but everything else is as simple as copy and paste.OBC_NAME=test01-obc OBC_NS=ai-testing BUCKET_HOST=$(oc get -n $OBC_NS configmap $OBC_NAME -o jsonpath='{.data.BUCKET_HOST}') BUCKET_NAME=$(oc get -n $OBC_NS configmap $OBC_NAME -o jsonpath='{.data.BUCKET_NAME}') BUCKET_PORT=$(oc get -n $OBC_NS configmap $OBC_NAME -o jsonpath='{.data.BUCKET_PORT}') BUCKET_KEY=$(oc get secret -n $OBC_NS $OBC_NAME -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 -d) BUCKET_SECRET=$(oc get secret -n $OBC_NS $OBC_NAME -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 -d) printf "\n" printf "BUCKET_HOST: $BUCKET_HOST \n" printf "BUCKET_NAME: $BUCKET_NAME \n" printf "BUCKET_PORT: $BUCKET_PORT \n" printf "BUCKET_KEY: $BUCKET_KEY \n" printf "BUCKET_SECRET: $BUCKET_SECRET \n"Now, the commands above will give you some very key things about your object bucket claim. The two most important are:
BUCKET_KEY- This is the AWS-based access keyBUCKET_SECRET- This is the AWS-based access secret key
You can also view your object buckets and object bucket claims within the OpenShift UI under Storage > Object Storage (see example below).
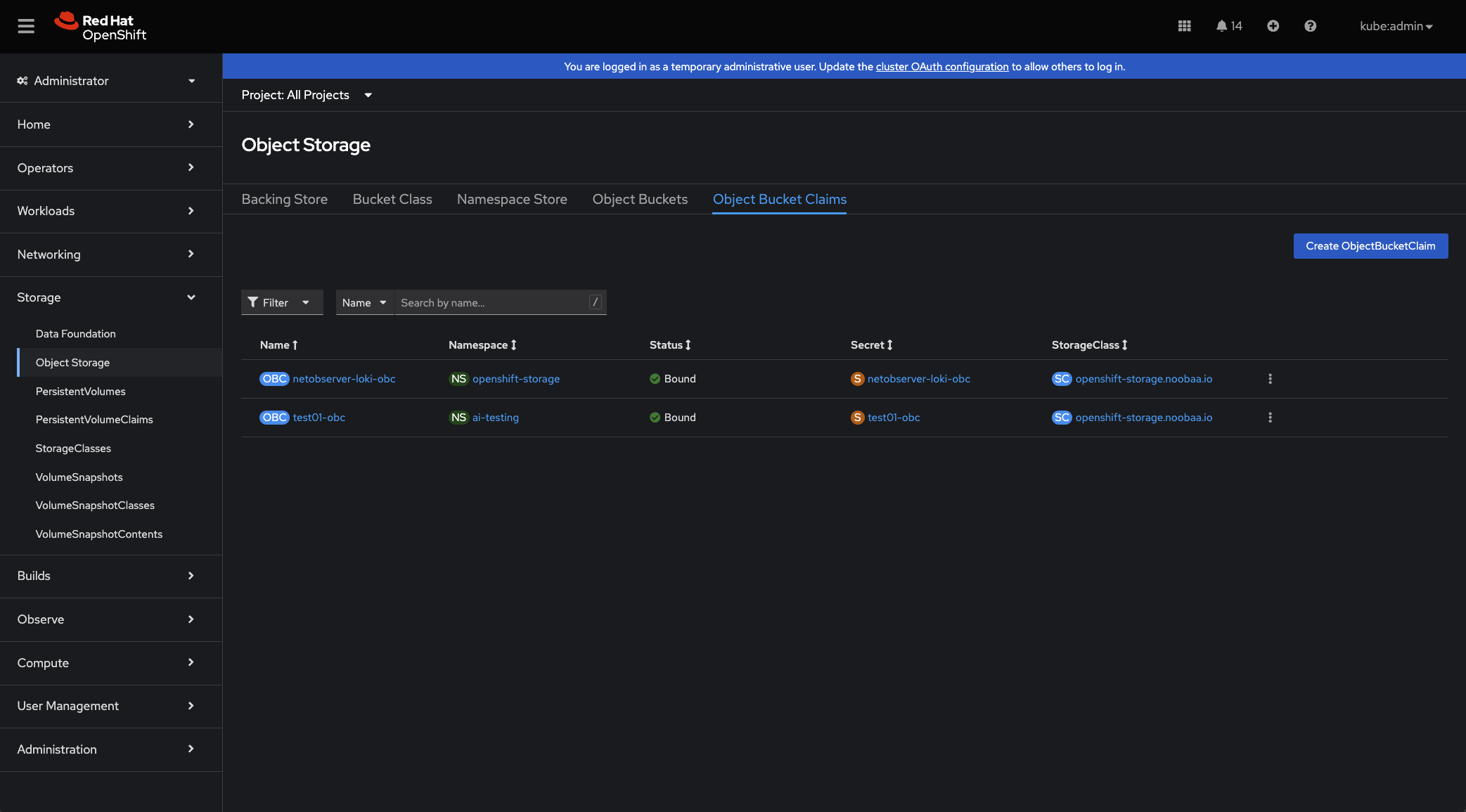
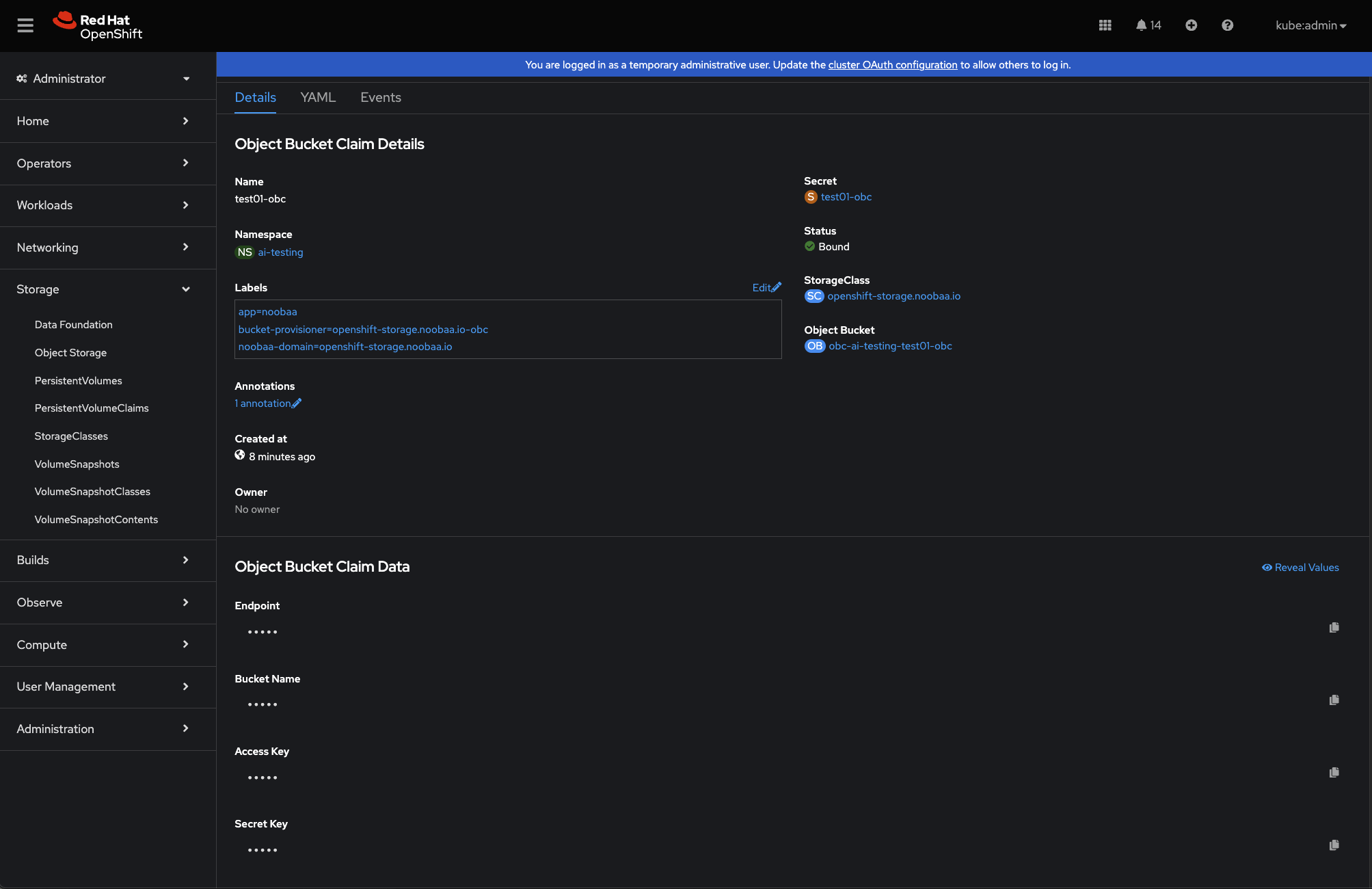
Part VI: Using S3 Object Buckets
Remember that part about using the AWS S3-based commands with the Multicloud Object Gateway? Well, let's put this to work, and see what we've got.
To use the S3 bucket, you need to export a couple of aws CLI variables, and include the --endpoint URL for your NooBaa instance within OpenShift. The NooBaa/MCG instance endpoint is a TLS endpoint, and is formatted like so:https://s3-openshift-storage.apps.demo.ai.ocp.run
In the example above, demo is the cluster name, while ai.ocp.run is the domain name. Take these into consideration with your own MCG deployment.
-
You can simply use the
awsCLI utility to work with your S3 buckets provided by the Multicloud Object Gateway (via NooBaa). Here's an example that will list the buckets deployed to your SNO environment:export AWS_ACCESS_KEY_ID=$BUCKET_KEY export AWS_SECRET_ACCESS_KEY=$BUCKET_SECRET ❯ aws --endpoint https://s3-openshift-storage.apps.demo.ai.ocp.run --no-verify-ssl s3 ls 2024-05-27 16:49:33 netobserver-loki-obc 2024-05-27 16:49:33 test01-obc
It's really that easy!
Final Thoughts
So, now that you've deployed the Multicloud Object Gateway, can you think of any projects you want to use it for? How about some AI projects? The MCG is a simple, yet great operator to leverage with your OpenShift deployment. And now that you've seen how to use it within your SNO environment, it should open up a whole list of new projects you can try out.


