

Simple LLM Co-Pilot for OpenShift Development
Author: Dylan Wong
"It is our job to create computing technology such that nobody has to program. And that the programming language is human."
- Jensen Huang
- Part I: GPT4ALL Local Inferencing
- Part II: Model Hardware Configuration
- Part III: Model Parameters
- Part IV: Implementing the Co-Pilot Logic
Introduction
Large Language Model inferencing has become mainstream for a while now, however, utilizing it to enhance the developer experience remains a complex challenge. Abstract thinking is key to leveraging inferencing models as a functional actor in a developers local environment.
In this exploration we try to achieve these capabilities within the context of Infrastructure as Code Development and Testing:
- Parse and execute complex commands, such as managing infrastructure or running tests.
- Maintain contextual awareness of the environment and project state.
- Provide real-time feedback and suggestions to enhance the developer experience.
We mimic what enums provide for states in traditional applications, for example <RUN_CDK_SYNTH> as a simple form of prompt engineering to signal specific actions on the CLI. These states provide minimal guard rails for responses by instructing the chat to interpret user input correctly and execute the relevant command within a predefined scope. This approach adds structure and reliability to natural language interactions.
The implications of these mechanisms for system specific AI Agents are significant, iterating and optimizing these mechanisms to extend our current capabilities beyond command execution such as; writing code to files for rapid prototyping or generating dynamic boilerplates.
Technically this implementation is a simple state machine in a general sense, as it handles different stages based on user input and the responses from the Local AI model. Here’s why:
- States: The script has different logical states, such as awaiting for user input, sending the input to the GPT4ALL Local API, processing the result, and executing the appropriate command (like
yarn synthoryarn test). - Transitions: The transitions between these states are determined by conditions, such as the specific enum returned by GPT (
<RUN_CDK_SYNTH>,<RUN_NPM_TEST>, etc.). - Actions: Based on the state and the corresponding transition, the script performs specific actions, such as running a CDK command, displaying output, or printing fun facts.
We will explore how to create a Co-Pilot for your IaC CLI tools with the GPT4ALL local API and simple bash scripting, enabling LLM inferences that run commands for you using natural language. The outlined approach combines the power of prompt engineering with the flexibility of the IaC frameworks to enhance the developer experience.
Of course, one can write this same implementation in Python, Go, Node.js, etc and take advantage of LLM tokenizer libraries and packages, Langchain, etc.
That being said, for sake of being as "dependency free" as possible, I opted for using Bash.
For demonstration purposes we are utilizing CDK8s in Typescript to define our Helm Values to generate a Custom Resource Definition that extends OpenShift Tekton to be used for validating and defining Pipeline Stages for CI/CD.
Note: CDK8s is the IaC framework we are using in this example, however we have tested this exercise using TFCDK and AWS CDK in Typescript
You can reference the completed solution in this overview below: https://gist.github.com/dylwong/8da4da95fdaa3f865af6af9f41708e43
The solution presented here is intended for educational and experimental purposes only. We strongly advise against using this approach in production environments, especially for managing critical infrastructure workloads, handling vaulted secrets, or operating within sensitive Kubernetes clusters.
Large Language Model (LLM) security is relative, and while LLMs can assist with many tasks, the attack surface is high if not implemented with best practices and may expose vulnerabilities or create uncertain risks.
For production and mission-critical workloads, compliance-driven environments, and any scenarios involving real world data or operations, we recommend keeping an eye out for OpenShift AI. OpenShift AI is designed with enterprise-grade security, scalability, and compliance in mind, making it the best option for running AI workloads in critical and regulated environments.
Requirements:
- You will need an inferencing API, in our case we are using GPT4ALL.
- NPM & Typescript (tsc) installed on your machine, as well as your IaC framework of choice installed in your project. (In this example we are using CDK8s)
First, you can start by installing GPT4ALL

(I am on MacOS but they have ports for Windows and Linux)
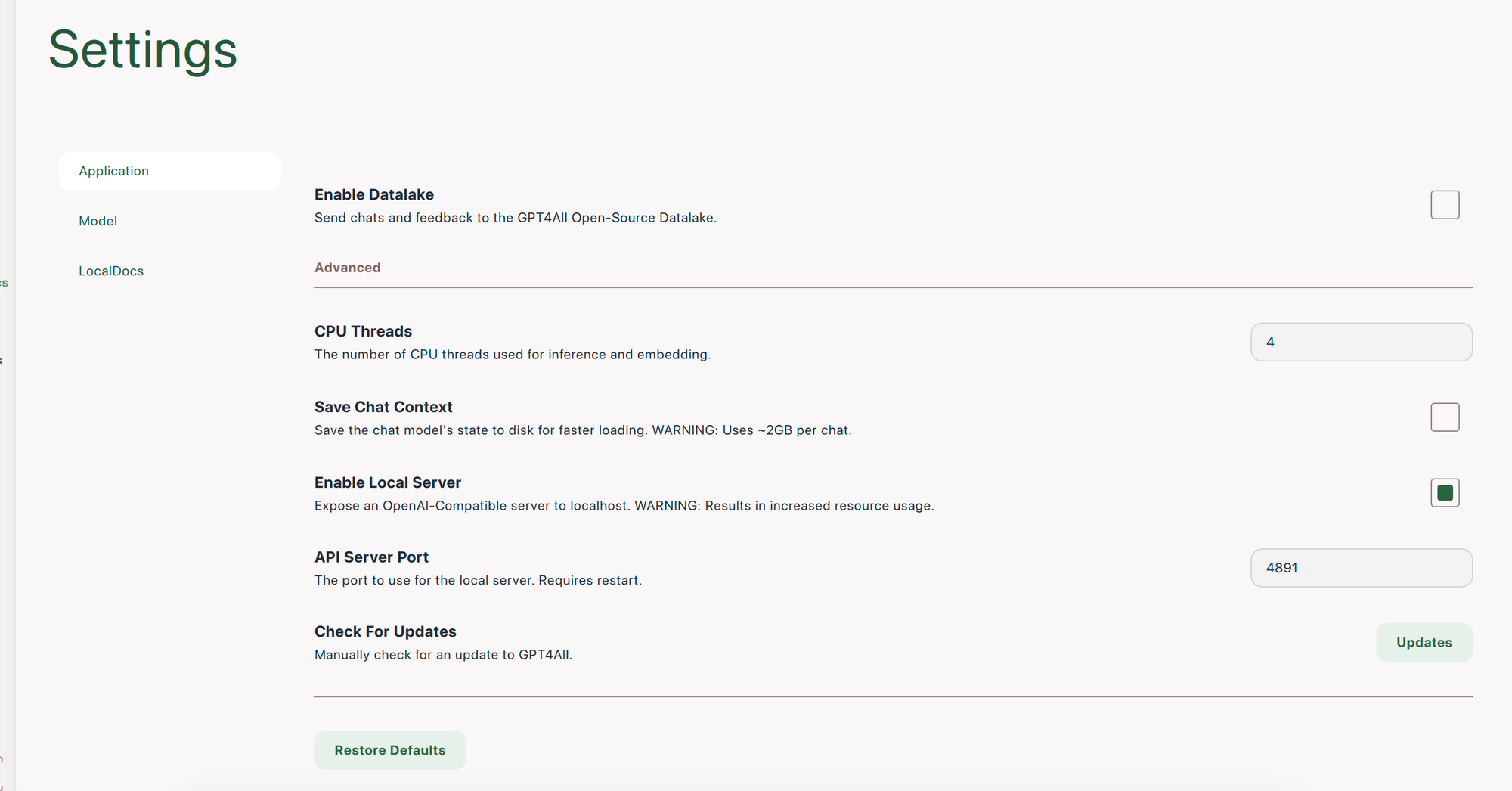
Part I: Enable Local Server on GPT4ALL
You can enable the HTTP Server via GPT4All Chat > Settings > Application > Enable Local Server. By default, it listens on port 4891 (the reverse of 1984)
Warning: Running GPT4ALL on a dedicated host on the same local network is recommended to mitigate performance issues
Part II: Configure Hardware Usage
In the same view on GPT4All Chat > Settings > Application, change the default device type to "metal". This will enable usage of your host's local GPU, in my case the Mac Mini M2 Pro has a 19 Core GPU, I am currently utilizing 32 GPU Layers.
A GPU layer refers to the transformer model's neural network layer loaded into VRAM (Video RAM) for processing. The more layers that can be handled by the GPU, the faster the model will perform, as it leverages parallel processing to speed up computations.


Part III: Defining Model Parameters
Now we will configure the parameters for our inferencing prompts.
Navigate to GPT4All Chat > Settings > Model
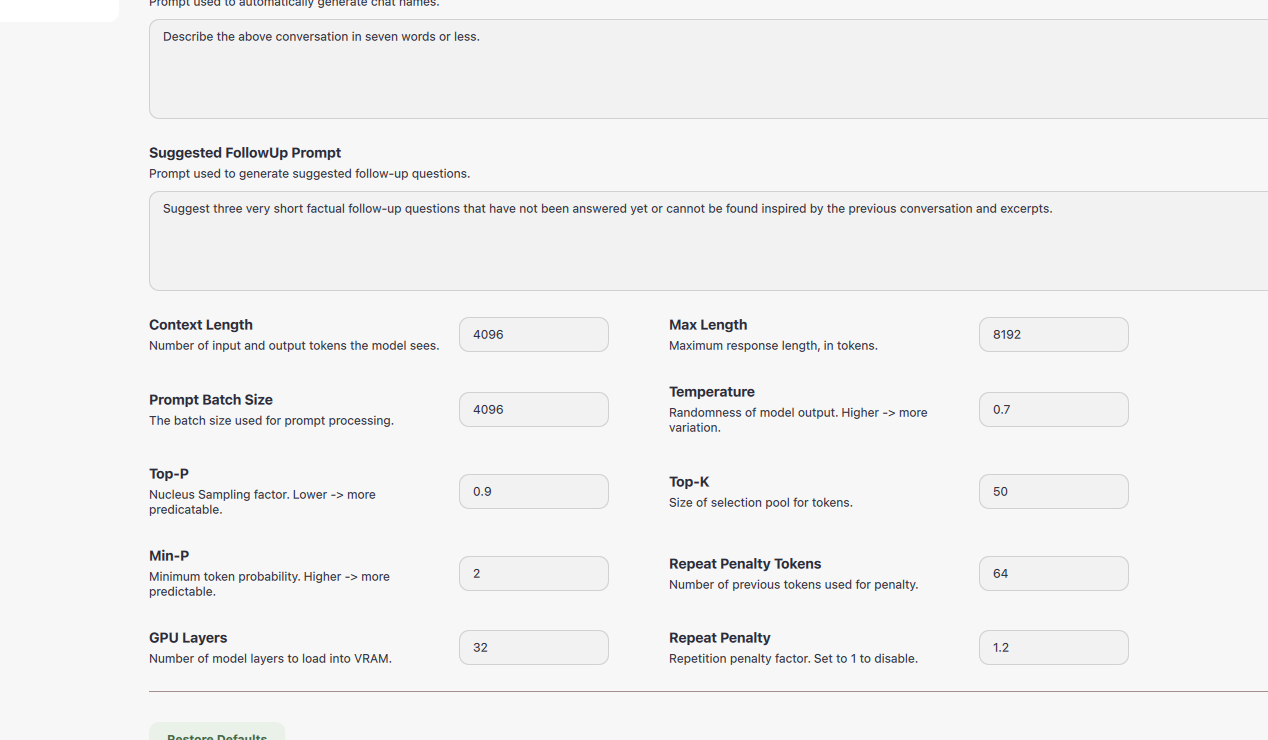
| Parameter | Value | Description |
|---|---|---|
| Context Length | 4096 | Allows processing of longer inputs |
| Max Tokens | 8192 | Ensures detailed responses without truncation. |
| Prompt Batch Size | 4096 | Balances speed and memory usage for batch processing. |
| Top-p | 0.9 | Keeps responses diverse but focused. |
| Min-p | 2 | Adds flexibility by considering less probable tokens when needed. |
| Repeat Penalty | 1.2 | Discourages token repetition, keeping responses concise. |
| Repeat Penalty Tokens | 64 | Applies penalty to the last 64 tokens to reduce redundancy. |
| Top-k | 50 | Limits the token sampling to the top 50 most likely tokens. |
| Temperature | 0.7 | Balances randomness and accuracy for reliable yet varied output. |
Part IV: Scripting your Co-Pilot
From here you can create a simple bash script in your project directory that will provide the REPL-style interface along with the curl commands that interface with the local API that GPT4ALL Exposes over HTTP.
1. Define Color Code Constants
The script begins by defining color codes for the terminal output and some ASCII art to enhance the user experience. These colors and animations are purely for aesthetic purposes, making the REPL more engaging.
nc='\033[0m' # No Color
turquoise='\033[0;36m'
pink='\033[0;35m'
green='\033[0;32m'
red='\033[0;31m'
yellow='\033[0;33m'
neon_green='\033[38;5;46m' # Neon Green
purple='\033[0;35m' # Purple
2. Typewriter Animation
This simple function provides a "typewriter" effect to the messages printed by the script, making it emulate HTTP streaming that many LLM API's provide such as OpenAI.
typewriter() {
local message=$1
while IFS= read -r line; do
for ((i=0; i<${#line}; i++)); do
echo -n "${line:$i:1}"
sleep 0.02 # Adjust for a nice typewriter effect
done
echo ""
done <<< "$message"
}
3. Fun Facts Messaging
To keep things engaging, the script has a few fun facts about OpenShift that are randomly printed after a command is executed.
fun_facts=(
"OpenShift is a Kubernetes distribution developed by Red Hat."
"It provides automated installation, updates, and lifecycle management throughout the container stack."
"OpenShift supports a wide range of programming languages, frameworks, and databases."
"It includes a built-in CI/CD pipeline for automated deployments."
"OpenShift focuses on developer productivity and security with features like Role-Based Access Control (RBAC)."
)
print_fun_fact() {
local random_index=$((RANDOM % ${#fun_facts[@]}))
echo -e "${yellow}Fun Fact: ${fun_facts[$random_index]}${nc}"
}
4. Define your Instructional Prompts
Because GPT4ALL is a desktop app, it persists messages even when inferenced via the API. This means we need to define the instructions and inference to the model on initial start up on the script instead of appending context to every following user-facing prompt to prevent hallucinations.
If you are using OpenAI GPT or other managed inferencing API services, you will have to utilize this prompt differently in your script due to them often being stateless by default.
The pre_prompt is responsible for guiding the GPT-based Co-Pilot on which commands it can interpret. These commands are defined in the Typescript project's package.json.
pre_prompt="You are a strict command parser. Your sole task is to detect user intent for running a command and return **only one** of these enums: <RUN_CDK_SYNTH>, <RUN_CDK_DEPLOY>, <RUN_CDK_DESTROY>, <RUN_NPM_TEST>, <RUN_CDK_BOOTSTRAP>."
The post_command_prompt is used to analyze the results of the executed commands and provide a clear summary in plain text:
post_command_prompt="You are a command output interpreter for humans. You will receive the results of CDK8s CLI commands. Your task is to provide a complete, plain-text analysis of the results, explaining any successes or errors."
5. Define your CLI Command Handler
The function run_cdk_command is responsible for actually executing the command that has been identified by GPT. It runs the command and simply stores the output in command_results.txt for logging.
# Function to run CDK commands
run_cdk_command() {
local command=$1
echo -e "${yellow}Running command: ${command}${nc}"
output=$(eval $command 2>&1)
echo "$output" > command_results.txt
echo -e "${neon_green}Command Result:${nc}"
cat command_results.txt
# Pass command results to GPT with post-command instructions
chat_with_gpt "$output" "$post_command_prompt"
}
# Send the pre-prompt to the inferencing API (this will set the initial context)
chat_with_gpt "$pre_prompt"
6. Define your Inferencing API Call
This simple function sends user input and a system prompt to the local GPT4ALL API using Mistral Instruct, parses the JSON response using jq, and displays the model's output with a typewriter animation. It facilitates natural language command execution by leveraging curl for POST requests and providing real-time interaction in the terminal while mimicking the streamed responses found in models such as GPT4o, etc.
Notice, that there is no "Authorization" header for JWT style credentials because this is running locally.
chat_with_gpt() {
local input=$1
local prompt=$2
# Escape input for JSON formatting
local escaped_input=$(jq -nR --arg v "$input" '$v')
# Send a request to the inferencing API
local response=$(curl -s -X POST \
-H "Content-Type: application/json" \
-d '{
"model": "Mistral Instruct",
"messages": [
{
"role": "system",
"content": "'"$prompt"'"
},
{
"role": "user",
"content": '"$escaped_input"'
}
]
}' \
"http://localhost:4891/v1/chat/completions")
# Extract the completion message from the response
local completion=$(echo "$response" | jq -r '.choices[0].message.content')
# Display the output with the typewriter effect
echo -e "${neon_green}DevOpsDylanGPT:${nc}"
typewriter "$completion"
if [[ "$completion" == *"<RUN_CDK_SYNTH>"* ]]; then
run_cdk_command "yarn synth"
elif [[ "$completion" == *"<RUN_CDK_BOOTSTRAP"* ]]; then
run_cdk_command "yarn bootstrap"
elif [[ "$completion" == *"<RUN_NPM_TEST>"* ]]; then
run_cdk_command "yarn test -u"
fi
}
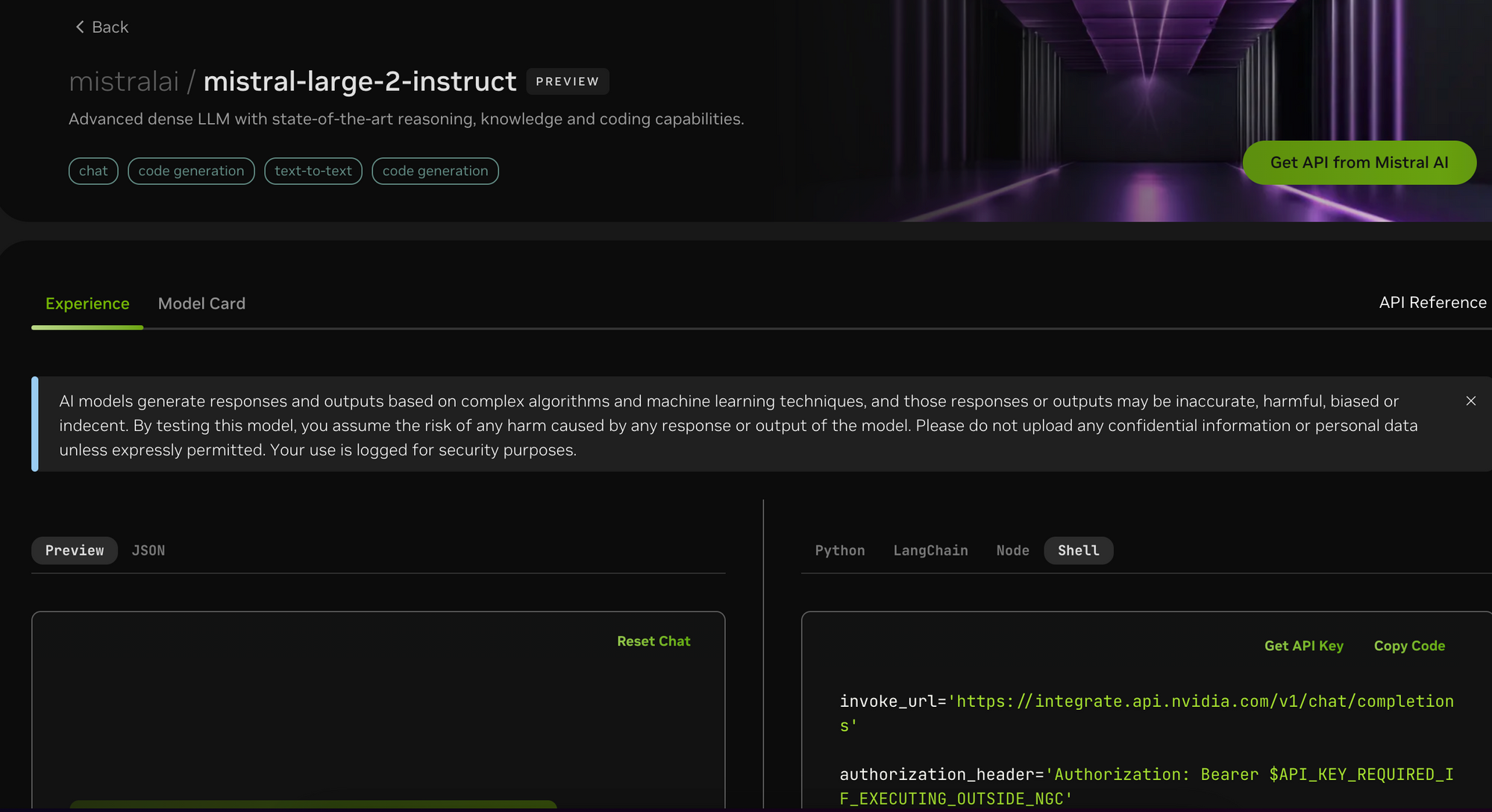
This version below uses the NVIDIA NIM API instead of GPT4ALL
chat_with_gpt() {
local input=$1
local language=$2
local extension=$(get_file_extension $language)
local escaped_input=$(jq -nR --arg v "$input" '$v')
# Update chat history
jq ". += [{\"role\": \"user\", \"content\": $escaped_input }]" "$history_file" > tmp_history.json && mv tmp_history.json "$history_file"
# Prepare the chat history for the request
local messages=$(jq -c '.' "$history_file")
local response=$(curl -s -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $API_KEY_HERE" -d "{\"model\": \"mistralai/mistral-large-2-instruct\", \"messages\": $messages}" "https://integrate.api.nvidia.com/v1/chat/completions")
local completion=$(echo $response | jq -r '.choices[0].message.content')
# completions are stateless in comparison to gp4all must persist context
jq ". += [{\"role\": \"assistant\", \"content\": $(jq -nR --arg v "$completion" '$v') }]" "$history_file" > tmp_history.json && mv tmp_history.json "$history_file"
echo -e "${neon_green}DevOpsDylanGPT:${nc}"
typewriter "$completion"
if [[ $input == *"CODE"* ]]; then
local file_name="generated_code.$extension"
echo "$completion" > "$file_name"
echo -e "${neon_green}DevOpsDylanGPT:${nc} Code written to ${file_name}"
fi
# Check for specific signals in the completion to run CDK commands
case "$completion" in
*"<RUN_CDK_SYNTH>"*)
run_cdk_command "yarn synth"
;;
*"<RUN_CDK_BOOTSTRAP>"*)
run_cdk_command "yarn bootstrap"
;;
*"<RUN_NPM_TEST>"*)
run_cdk_command "yarn test"
;;
esac
}
In the case that the inferencing response object includes the specific tags like <RUN_CDK_SYNTH>, <RUN_CDK_DEPLOY>, or <RUN_NPM_TEST>, the script will execute the corresponding commands.
The command cdk synth will render the following CRD and Tekton Resource YAML Files via the defined Typescript Classes via the fields passed to our class constructors.
Typescript CDK Class Instance Definitions
const app = new App();
const props = {
stage: 'unit',
tests: ['echo_test'],
namespace: 'default',
releaseName: 'my-release',
};
new TektonResources(app, 'tekton-resources', props);
new FirelineCrdChart(app, 'fireline-crd-chart');
app.synth();
CRD YAML File
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: firelines.tekton.dev
spec:
conversion:
strategy: None
group: tekton.dev
names:
kind: Fireline
plural: firelines
shortNames:
- fl
singular: fireline
scope: Namespaced
versions:
- name: v1
schema:
openAPIV3Schema:
properties:
spec:
properties:
stages:
items:
enum:
- Unit
- Integration
- Systems
- Acceptance
type: string
type: array
type: object
type: object
served: true
storage: true
Tekton Resources YAML
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
labels:
app.kubernetes.io/instance: unit
app.kubernetes.io/name: fireline-chart-name-unit
name: fireline-pipeline-unit
namespace: default
spec:
tasks:
- name: fireline-pipeline-echo_test
---
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
labels:
apps.openshift.io/instance: my-release
apps.openshift.io/name: fireline-chart-name-my-release
name: fireline-pipelinerun-my-release
namespace: default
spec:
pipelineRef:
name: fireline-pipeline-my-release
---
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
labels:
apps.openshift.io/instance: my-release
apps.openshift.io/name: fireline-chart-name-my-release
name: fireline-task-unit
namespace: default
7. Define the User Input Function
Once the system is initialized, the pre-prompt is sent to the GPT model to set the context for what type of commands the user might input. This ensures that the model knows to expect CDK commands and how to respond appropriately. Then, the script enters a REPL loop that continuously listens for user input. If the user wants to exit, they simply type "exit". Otherwise, the input is processed by GPT.
# Send pre-prompt to your Inferencing function on initilization
echo -e "${turquoise}Entering DevOpsGPT REPL...${nc}"
while true; do
read -r "input?You: "
if [ "$input" = "exit" ]; then
echo -e "${turquoise}Exiting DevOpsGPT REPL...${nc}"
break
else
# Chat with DevOpsDylanGPT
chat_with_gpt "$input" "$pre_prompt"
# Check for command results
if [ -s "command_results.txt" ]; then
echo -e "${neon_green}Command Result:${nc}"
cat command_results.txt
echo "" > command_results.txt # Clear the results file after reading
fi
fi
done
That's all folks! Here's a few demo videos below:
Here is another example where I used mistral-large-2-instruct NVIDIA NIM Inferencing API in the Public Cloud, the performance is much better:
Note: The NVIDIA NIM API supports Open AI API Compliance which requires a Bearer Token, it also features stateless inferencing with the completions endpoints, which meant I had to append and serialize previous chat logs for contextually aware prompts.
TODO
Implement experiment with model deployed on OpenShift AI